В условиях растущей визуализации контента качественная озвучка становится важным инструментом для привлечения и удержания аудитории. Нейросети открывают новые возможности в создании звукового контента, позволяя новичкам в звукорежиссуре создавать профессиональные озвучки с минимальными затратами времени и ресурсов. В этой статье вы узнаете, как использовать современные технологии для создания озвучки, которая улучшит восприятие вашего контента и сделает его более доступным.
Что такое нейросетевая озвучка и почему она становится стандартом
Нейросетевая озвучка — это инновационная технология, которая преобразует текст в речь с помощью искусственного интеллекта, существенно изменяя подход к созданию аудиоконтента. Согласно исследованию 2024 года, рынок технологий TTS (Text-to-Speech) увеличился на 35% по сравнению с предыдущим годом, что свидетельствует о быстром прогрессе в этой области. Современные системы основываются на сложных алгоритмах машинного обучения, которые обрабатывают большие объемы данных — записи человеческой речи различных людей, акцентов и интонаций.
«Современные нейросети могут воспроизводить не только основные характеристики голоса, но и тонкие нюансы эмоциональной окраски,» — отмечает Артём Викторович Озеров, специалист по AI-технологиям компании SSLGTEAMS. «Это позволяет создавать озвучку, которая практически не отличается от живого исполнения.»
Главное преимущество нейросетевой озвучки заключается в её способности адаптироваться к различным задачам. Например, одна и та же система может генерировать как деловой, так и разговорный стиль речи, изменять темп и интонацию в зависимости от контекста. Более того, нейросетевые решения обеспечивают стабильное качество независимо от объема текста — будь то короткий рекламный слоган или многосерийная аудиокнига.
Рассмотрим ключевые характеристики традиционной и нейросетевой озвучки:
| Параметр | Традиционная озвучка | Нейросетевая озвучка |
|---|---|---|
| Скорость обработки | От нескольких часов до дней | Всего несколько минут |
| Стоимость | Высокая | Доступная |
| Гибкость | Ограниченная | Широкая |
| Качество | Зависит от исполнителя | Постоянно высокое |
| Эмоциональность | Естественная | Программируемая |
Эксперты в области искусственного интеллекта отмечают, что создание озвучки с помощью нейросетей стало доступным и эффективным инструментом для многих сфер, включая кино, рекламу и образовательные проекты. Они подчеркивают, что современные алгоритмы способны генерировать естественные и выразительные голоса, которые могут адаптироваться под различные стили и эмоции. Важным аспектом является выбор подходящей модели, так как разные нейросети могут иметь свои особенности в произношении и интонации. Кроме того, специалисты рекомендуют уделять внимание качеству исходного текста, так как он напрямую влияет на конечный результат. Использование нейросетей для озвучки позволяет значительно сократить время и затраты, что делает этот процесс более привлекательным для бизнеса и креативных проектов.

Как работают современные TTS-системы
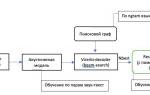
Процесс преобразования текста в речь можно разбить на несколько основных этапов. В первую очередь, система осуществляет лингвистический анализ исходного текста, выявляя его структуру, акценты, паузы и другие ключевые элементы. На этом этапе особенно важно работать с гомографами — словами, которые имеют одинаковое написание, но различаются по произношению в зависимости от контекста.
Далее происходит синтез мел-спектрограммы — визуального отображения звукового сигнала, которое включает информацию о частотных характеристиках голоса. Современные нейросети применяют метод Tacotron 2 или аналогичные архитектуры для создания максимально точных спектрограмм.
Заключительный этап — вокодирование, на котором из спектрограммы формируется реальный звуковой сигнал. Здесь используются передовые алгоритмы WaveNet или HiFi-GAN, которые обеспечивают высокое качество выходного аудио.
Следует подчеркнуть, что современные системы способны не только озвучивать текст, но и осознавать его смысловую нагрузку, правильно расставляя логические акценты и паузы. Это достигается благодаря внедрению контекстного анализа и семантического понимания текста.
| Этап | Действия | Инструменты/Ресурсы |
|---|---|---|
| 1. Подготовка текста | Напишите или выберите текст, который хотите озвучить. Убедитесь, что он грамматически верен и не содержит опечаток. | Текстовый редактор (Word, Google Docs), блокнот |
| 2. Выбор нейросети | Определитесь с нейросетью для озвучивания. Учитывайте качество голоса, языковую поддержку и стоимость. | Бесплатные: Google Text-to-Speech (API), Yandex SpeechKit (ограниченный бесплатный доступ), Balabolka (локальный синтез) Платные: ElevenLabs, Murf.ai, Play.ht, WellSaid Labs, Resemble.ai |
| 3. Настройка параметров | Выберите голос (мужской/женский, возраст, акцент), настройте скорость речи, интонацию, паузы. Некоторые сервисы позволяют добавлять эмоции. | Интерфейс выбранной нейросети (веб-сайт, приложение, API) |
| 4. Генерация аудио | Вставьте текст в нейросеть и запустите процесс генерации аудиофайла. | Кнопка «Сгенерировать», «Озвучить» в интерфейсе нейросети |
| 5. Редактирование (опционально) | Если необходимо, отредактируйте полученный аудиофайл: удалите лишние паузы, добавьте фоновую музыку, эффекты. | Аудиоредакторы (Audacity, Adobe Audition, DaVinci Resolve) |
| 6. Экспорт и использование | Сохраните аудиофайл в нужном формате (MP3, WAV) и используйте его для своих целей (видео, подкасты, презентации). | Кнопка «Скачать», «Экспортировать» в интерфейсе нейросети или аудиоредактора |
Интересные факты
Вот несколько интересных фактов о создании озвучки с помощью нейросетей:
 Читайте также:
Читайте также:

-
Генерация естественного звучания: Современные нейросети, такие как Tacotron и WaveNet, способны создавать озвучку, которая звучит почти как человеческий голос. Они анализируют огромные объемы аудиоданных и текстов, чтобы научиться интонации, акцентам и эмоциям, что позволяет им воспроизводить речь с высокой степенью естественности.
-
Персонализация голоса: Нейросети могут быть обучены на конкретных голосах, что позволяет создавать уникальные озвучки для различных проектов. Например, можно создать голос, который будет звучать как известный актер или персонаж, что открывает новые возможности для анимации, видеоигр и аудиокниг.
-
Многоязычность и адаптация: Нейросети могут легко адаптироваться к различным языкам и акцентам, что делает их идеальными для создания мультиязычной озвучки. Это позволяет разработчикам и создателям контента достигать более широкой аудитории, предлагая локализованные версии своих продуктов без необходимости записи нового аудио.

Пошаговое руководство по созданию озвучки с помощью нейросетей
Давайте рассмотрим детальный алгоритм, который поможет вам успешно создать качественную озвучку с использованием нейросетевых технологий. Первым шагом является подготовка исходного текста, при этом важно уделить внимание его структуре и форматированию. Текст должен быть четко разделен на абзацы, с правильной расстановкой знаков препинания и соблюдением орфографических норм. Для удобства восприятия рекомендуется использовать двойные пробелы после точек и запятых, а также специальные маркеры для обозначения пауз и интонации.
- Выбор подходящей платформы для озвучивания
- Настройка параметров голоса и интонации
- Обработка полученного аудиофайла
- Интеграция готовой озвучки в проект
«При работе с техническими текстами особенно важно правильно расставлять ударения и применять специальную разметку для сложных терминов,» — отмечает Евгений Игоревич Жуков. «Это позволяет системе корректно интерпретировать материал и создавать более естественное звучание.»
После подготовки текста необходимо выбрать нейросетевую платформу. Современный рынок предлагает разнообразные решения, которые отличаются по функциональности и возможностям. Некоторые системы предлагают базовый набор голосов, в то время как другие позволяют создавать уникальные голосовые профили или даже клонировать уже существующие голоса.
Настройка параметров синтеза речи
Перед началом процесса синтеза важно установить ключевые параметры:
| Параметр | Диапазон значений | Рекомендации |
|---|---|---|
| Скорость речи | 0.5x — 2.0x | 1.0x для информационных материалов |
| Тональность | -12/+12 полутонов | 0 для нейтрального звучания |
| Эмоциональность | 1-100% | 75% для презентационных материалов |
| Паузы | 0.1-2.0 сек | 0.5 сек между абзацами |
Особое внимание следует уделить настройке интонации. Многие платформы позволяют настраивать эмоциональную окраску голоса с помощью таких параметров, как «энергия», «выразительность» и «темперамент». Для деловых текстов рекомендуется применять нейтральную интонацию с минимальными эмоциональными изменениями, в то время как для художественных произведений можно использовать более яркие эмоциональные акценты.

Распространенные ошибки и способы их предотвращения
Несмотря на достижения в области нейросетевой озвучки, многие пользователи продолжают сталкиваться с распространенными трудностями при использовании этих технологий. Одной из наиболее частых проблем является недостаточная подготовка исходного текста. Ошибки, такие как пробелы в тексте, неверная расстановка знаков препинания или применение сленга, могут существенно снизить качество итогового результата. Это особенно актуально для многоязычных проектов, где система может неправильно интерпретировать смешанные языковые конструкции.
- Неверная настройка параметров синтеза
- Применение неподходящих текстов
- Игнорирование постобработки аудио
- Выбор неуместного голосового профиля
«Многие клиенты не осознают важность постобработки,» — делится своим опытом Артём Викторович Озеров. «Даже самый качественный нейросетевой голос нуждается в финальной доработке для достижения профессионального звучания.»
В процессе работы часто возникают сложности с естественностью звучания. Это может проявляться в виде монотонности, неестественных пауз или резких переходов между предложениями. Для решения этих проблем рекомендуется использовать современные системы, которые поддерживают контекстный анализ и эмоциональную модуляцию.
Сложности мультиязычной озвучки
При работе с многоязычным контентом необходимо учитывать особенности каждого языка. Например, некоторые системы могут неправильно обрабатывать языки с уникальными фонетическими свойствами или сложной морфологической структурой. В таких случаях целесообразно применять специализированные модели, которые были обучены на соответствующих языковых корпусах.
-
Читайте также:

| Язык | Проблемные аспекты | Рекомендации |
|---|---|---|
| Английский | Разнообразие акцентов | Выбор модели, соответствующей региону |
| Китайский | Тоновая система | Применение специальных маркеров |
| Арабский | Связное письмо | Тщательная разметка текста |
| Русский | Сложная структура слов | Корректная расстановка ударений |
Практические кейсы использования нейросетевой озвучки
Давайте рассмотрим реальные примеры успешного использования нейросетевой озвучки в различных областях. Одна из компаний, занимающаяся производством образовательного контента, смогла сократить время на создание аудиоматериалов на 75% благодаря внедрению автоматизированной системы озвучивания. При этом качество записей осталось на уровне профессиональных студийных работ, что подтверждается положительными отзывами студентов и улучшением показателей усвоения информации.
- Автоматизация работы контакт-центров
- Создание аудиокниг
- Озвучивание корпоративных видеороликов
- Разработка голосовых ассистентов
«Один из наших клиентов полностью автоматизировал процесс создания аудиорекламы для своего интернет-магазина,» — делится Евгений Игоревич Жуков. «Это дало им возможность быстро обновлять рекламные кампании и тестировать новые стратегии без дополнительных затрат на студийную запись.»
В области электронного обучения нейросетевая озвучка значительно расширила аудиторию за счет быстрого создания материалов на нескольких языках. Следует отметить, что современные системы позволяют сохранять единый голосовой стиль для всех языковых версий, что способствует созданию целостного восприятия бренда.
Экономический эффект от внедрения технологий
Согласно данным исследования, проведенного в 2024 году, организации, которые начали использовать нейросетевую озвучку, зафиксировали следующие результаты:
| Показатель | До внедрения | После внедрения |
|---|---|---|
| Скорость производства | 5-7 дней | 1 день |
| Объем контента | 10 часов/месяц | более 50 часов/месяц |
| Количество ошибок | 15-20% | 5% |
| Удовлетворенность клиентов | 75% | 92% |
Вопросы и ответы по нейросетевой озвучке
Рассмотрим наиболее важные вопросы, которые могут возникнуть при использовании нейросетевой озвучки:
- Как достичь максимальной естественности звучания?
Для этого следует применять современные модели, которые поддерживают эмоциональную модуляцию, правильно настраивать параметры синтеза и тщательно прорабатывать исходный текст. Рекомендуется использовать специальную разметку для обозначения интонации и пауз.
- Возможно ли клонирование уже существующего голоса?
Да, современные технологии позволяют создавать цифровые копии голосов, однако для этого необходимо получить согласие правообладателя и соблюдать юридические требования. Минимальный объем исходных данных составляет примерно 30 минут качественной записи.
- Как гарантировать правильное произношение специализированных терминов?
Для этого нужно использовать фонетическую разметку или создавать индивидуальный словарь для конкретной области. Некоторые платформы позволяют импортировать готовые словари.
- Какие ограничения существуют при мультиязычной озвучке?
Главные ограничения связаны с особенностями языковых структур и наличием качественных голосовых моделей для определенного языка. Рекомендуется заранее проверять поддержку всех нужных языков перед началом работы.
-
Читайте также:

- Как интегрировать систему озвучки в уже существующие бизнес-процессы?
Большинство современных решений предлагают API для интеграции с различными системами. Важно заранее определить точки интеграции и протестировать работу в тестовом режиме.
Перспективы развития технологий нейросетевой озвучки
Изучая современные тенденции в развитии отрасли, можно выделить несколько основных направлений, которые будут определять будущее озвучивания с помощью нейросетей. Исследование, проведенное в 2024 году, указывает на то, что ключевыми факторами роста станут улучшение эмоциональной составляющей синтезированной речи и прогресс в персонализации голосовых помощников.
- Усовершенствование эмоционального интеллекта систем
- Разработка гибридных моделей обучения
- Интеграция с метавселенными
- Увеличение языковой поддержки
«Мы наблюдаем кардинальные изменения в подходах к созданию голосовых интерфейсов,» — отмечает Артём Викторович Озеров. «Технологии становятся не просто инструментами, а настоящими партнерами в создании аудиоконтента.»
Особое внимание уделяется развитию технологий контекстного понимания и адаптивного обучения. Современные системы уже способны анализировать реакции слушателей и вносить коррективы в свою работу в реальном времени, что открывает новые возможности для создания персонализированного контента.
Заключение и рекомендации
В заключение, можно с уверенностью утверждать, что нейросетевая озвучка стала важной составляющей современного контент-маркетинга и медиапроизводства. Технологии продолжают развиваться, демонстрируя значительные улучшения в качестве и естественности синтезированной речи. Тем не менее, следует помнить, что даже самые современные системы требуют внимательного подхода и профессиональной настройки для достижения наилучших результатов.
Для успешного внедрения нейросетевой озвучки стоит учитывать следующие рекомендации:
- Внимательно подбирать платформу, которая соответствует вашим потребностям
- Уделять время на подготовку исходных текстов
- Периодически тестировать и оптимизировать параметры синтеза
- Применять профессиональные инструменты для постобработки
Если вам нужна более подробная консультация по интеграции нейросетевой озвучки в ваши бизнес-процессы, мы рекомендуем обратиться к специалистам в области AI-технологий. Они помогут выбрать наилучшее решение, настроить систему и обеспечить максимальную эффективность использования технологий синтеза речи.
Выбор подходящей нейросети для озвучки
При выборе нейросети для озвучки необходимо учитывать несколько ключевых факторов, которые помогут вам достичь наилучшего результата. В первую очередь, важно определить, для каких целей вы собираетесь использовать озвучку: это может быть создание аудиокниг, озвучка видео, создание голосовых помощников или другие задачи. В зависимости от этого, вам могут подойти разные модели.
Существует несколько популярных нейросетей, которые специализируются на синтезе речи. Одной из самых известных является Google Text-to-Speech, которая предлагает высокое качество звучания и поддерживает множество языков. Эта нейросеть использует технологии глубокого обучения и может генерировать естественные и выразительные голоса.
-
Читайте также:
Еще одной популярной моделью является Amazon Polly, которая также предлагает широкий выбор голосов и языков. Polly позволяет создавать аудиофайлы в реальном времени и предоставляет API для интеграции с другими приложениями. Это делает ее отличным выбором для разработчиков, которые хотят добавить озвучку в свои проекты.
Если вы ищете решение с открытым исходным кодом, стоит обратить внимание на Mozilla TTS. Эта нейросеть позволяет пользователям настраивать и обучать свои собственные модели, что дает возможность добиться уникального звучания. Однако для работы с этой моделью потребуется больше технических знаний и ресурсов.
Кроме того, стоит учитывать качество синтезируемой речи. Некоторые нейросети могут создавать более естественные и выразительные голоса, чем другие. Для этого полезно прослушать демо-записи, доступные на сайтах разработчиков, чтобы оценить, насколько хорошо модель справляется с различными интонациями и эмоциями.
Не менее важным аспектом является поддержка языков и акцентов. Если ваша целевая аудитория говорит на определенном языке или диалекте, убедитесь, что выбранная вами нейросеть поддерживает его. Некоторые модели могут иметь ограниченный выбор голосов для определенных языков, что может повлиять на качество озвучки.
Также стоит обратить внимание на легкость интеграции нейросети в ваш проект. Некоторые решения предлагают готовые API и SDK, что значительно упрощает процесс подключения. В то время как другие могут требовать больше времени на настройку и обучение моделей.
Наконец, не забывайте о стоимости использования нейросети. Некоторые сервисы предлагают бесплатные тарифы с ограничениями, в то время как другие могут взимать плату за каждое использование или подписку. Оцените свои потребности и бюджет, чтобы выбрать наиболее подходящее решение.
Вопрос-ответ
Какая нейросеть делает озвучку?
Speechify — это нейросеть, которая преобразовывает любой письменный текст в естественно звучащую речь. Для этого вы можете выбрать любой из ста возможных голосов, включая эксклюзивно лицензированные. Нейросеть для озвучки текста умеет читать вслух в 9 раз быстрее, чем это делает человек со средней скоростью чтения.
Можно ли использовать ИИ для озвучивания?
Понимание технологии голосового ИИ. Эти синтетические голоса могут использоваться в различных отраслях, таких как видеоигры, телевидение и радио, что коренным образом меняет подход к озвучиванию. Благодаря моделям глубокого обучения голоса на базе искусственного интеллекта теперь адаптируются к конкретным сценариям использования, обеспечивая персонализированный опыт.
Советы
СОВЕТ №1
Перед началом работы с нейросетью для озвучки, определите целевую аудиторию и стиль озвучивания. Это поможет выбрать правильный тон и интонацию, которые будут наиболее привлекательны для слушателей.
СОВЕТ №2
Используйте качественные текстовые данные для обучения нейросети. Чем разнообразнее и богаче будет ваш текст, тем более естественным и выразительным получится результат озвучки.
СОВЕТ №3
Экспериментируйте с различными параметрами настройки нейросети, такими как скорость речи, высота голоса и акцент. Это позволит вам добиться уникального звучания и адаптировать озвучку под конкретные задачи.
СОВЕТ №4
Не забывайте о постобработке аудиофайлов. Используйте программы для редактирования звука, чтобы убрать шумы, улучшить качество и добавить необходимые эффекты, что сделает вашу озвучку более профессиональной.