Умение эффективно сканировать и распознавать текст стало важным навыком для работы с документами и данными. Эта статья познакомит вас с современными технологиями и инструментами, позволяющими быстро и точно преобразовывать печатный текст в цифровой формат. Вы узнаете о методах и программном обеспечении, которые упростят вашу работу, сэкономят время и повысят продуктивность в условиях цифровой трансформации.
Основные методы сканирования и распознавания текста
Процесс перевода бумажных документов в цифровой формат требует знания различных методов и технологий. Существует несколько ключевых способов сканирования, каждый из которых обладает своими характеристиками и сферами применения. Первый способ – это планшетные сканеры, которые представляют собой устройства с гладкой стеклянной поверхностью, на которую укладывается документ. Этот метод наиболее популярен благодаря высокому качеству получаемых изображений и удобству в использовании. Однако, когда речь идет о больших объемах работы, он может не быть самым эффективным вариантом.
Второй способ – это протяжные сканеры, которые автоматически захватывают документ и пропускают его через сканирующий механизм. Они особенно полезны при обработке больших массивов документов, так как способны сканировать до 50-100 страниц в минуту. Евгений Игоревич Жуков, специалист компании SSLGTEAMS, отмечает: «При выборе сканера следует учитывать не только скорость, но и качество сканирования, особенно если документы содержат мелкий текст или сложные графические элементы». Третий способ – мобильное сканирование с помощью смартфонов и планшетов, которое стало особенно популярным благодаря появлению специализированных приложений.
Распознавание текста осуществляется с применением технологий OCR (оптическое распознавание символов). Современные OCR-системы способны не только распознавать стандартные шрифты, но и работать с рукописным текстом, таблицами и даже поврежденными документами. Артём Викторович Озеров делится своим опытом: «Многие пользователи недооценивают значимость предварительной подготовки документа к сканированию. Правильное освещение, устранение складок и загрязнений могут существенно повысить точность распознавания».
- Прямое сканирование оригиналов
- Сканирование через прозрачную пленку
- Использование многофункциональных устройств
- Автоматическое двухстороннее сканирование
- Беспроводная передача отсканированных документов
| Метод сканирования | Преимущества | Ограничения |
|---|---|---|
| Планшетный сканер | Высокое качество изображения, универсальность | Низкая скорость при большом объеме |
| Протяжный сканер | Высокая производительность, автоматизация | Ограничения по типу документов |
| Мобильное сканирование | Мобильность, доступность | Зависимость от условий освещения |
Эксперты в области обработки информации отмечают, что сканирование и распознавание текста стали неотъемлемой частью современного документооборота. Для достижения наилучших результатов важно использовать качественные сканеры, которые обеспечивают высокое разрешение и четкость изображений. Специалисты рекомендуют выбирать программное обеспечение с поддержкой оптического распознавания символов (OCR), которое позволяет преобразовывать изображения текста в редактируемый формат.
Кроме того, эксперты подчеркивают значимость предварительной подготовки документов: важно, чтобы страницы были чистыми и ровными, без складок и помятостей. Также стоит обратить внимание на выбор шрифтов и их размер, так как это напрямую влияет на точность распознавания. В заключение, специалисты советуют регулярно обновлять программное обеспечение для повышения эффективности работы и минимизации ошибок при распознавании текста.

Пошаговый процесс сканирования и распознавания
Процесс перевода бумажного документа в цифровой текст можно разбить на несколько последовательных шагов, каждый из которых требует внимательного подхода и корректной настройки. Все начинается с подготовки документа: необходимо убрать все скрепки, степлеры и другие металлические элементы, которые могут повредить сканер. Документ должен быть чистым, без серьезных загрязнений и повреждений. Особое внимание стоит уделить качеству печати – бледный или слишком жирный текст может значительно снизить точность распознавания.
На втором этапе осуществляется само сканирование документа. Здесь важно правильно выбрать режим сканирования: черно-белый, градации серого или цветной. Для текстовых документов обычно рекомендуется использовать режим градаций серого с разрешением 300 dpi, что обеспечивает оптимальное соотношение между качеством и размером файла. При сканировании документов с фотографиями или цветными элементами следует выбирать цветной режим с более высоким разрешением. Необходимо помнить, что увеличение разрешения приводит к увеличению размера файла и времени обработки, поэтому важно находить баланс между качеством и производительностью.
Третий этап – это обработка полученного изображения. Современные программы для сканирования часто включают функции автоматической коррекции перекоса, улучшения контрастности и удаления шумов. Эти функции особенно актуальны при работе с документами низкого качества или старыми бумагами. После этого начинается процесс распознавания текста, который может занять от нескольких секунд до нескольких минут в зависимости от объема документа и мощности оборудования. На этом этапе система анализирует изображение, определяет расположение текстовых блоков, таблиц, изображений и других элементов макета.
Четвертый этап – проверка и редактирование распознанного текста. Даже самые современные OCR-системы могут допускать ошибки, особенно при работе с нестандартными шрифтами, рукописным текстом или документами с повреждениями. Поэтому важно тщательно проверить результат распознавания и внести необходимые исправления. Многие программы предлагают возможность одновременного просмотра исходного изображения и распознанного текста, что значительно упрощает процесс корректировки. На финальном этапе документ сохраняется в нужном формате – DOCX, PDF или TXT, в зависимости от дальнейших задач использования.
| Метод сканирования | Преимущества | Недостатки |
|---|---|---|
| Использование смартфона (приложения) | Доступность, простота использования, мобильность, часто бесплатные приложения | Качество зависит от камеры и освещения, может быть неточным для больших объемов текста, ограниченные функции OCR |
| Использование планшетного сканера | Высокое качество сканирования, точное распознавание текста, подходит для книг и документов, возможность сканирования в высоком разрешении | Требует физического устройства, менее мобилен, занимает место, может быть дороже |
| Использование многофункционального устройства (МФУ) | Объединяет функции принтера, сканера и копира, удобно для офиса/дома, хорошее качество сканирования | Большие размеры, может быть дороже, чем отдельный сканер, не всегда оптимален для специфических задач |
| Использование онлайн-сервисов OCR | Не требует установки ПО, доступность с любого устройства, часто бесплатные или с пробным периодом | Зависит от интернет-соединения, вопросы конфиденциальности данных, ограничения по размеру файлов, может быть менее точным для сложных документов |
| Использование специализированного ПО для OCR (например, ABBYY FineReader) | Высочайшая точность распознавания, поддержка множества языков, расширенные функции редактирования и экспорта, пакетная обработка | Требует покупки лицензии, установка на компьютер, может быть сложным для новичков |
Интересные факты
Вот несколько интересных фактов о процессе сканирования и распознавания текста:
-
OCR и его история: Технология оптического распознавания символов (OCR) начала развиваться в 1920-х годах. Первые системы были довольно примитивными и использовали механические устройства для распознавания текста. Современные OCR-системы, такие как Tesseract, используют алгоритмы машинного обучения и нейронные сети, что значительно увеличивает точность распознавания.
-
Многоязычность: Современные OCR-системы могут распознавать текст на множестве языков и даже учитывать различные шрифты и стили написания. Это делает их полезными для работы с многоязычными документами, что особенно актуально в глобализированном мире.
-
Применение в различных сферах: Технология распознавания текста находит применение не только в сканировании документов, но и в таких областях, как автоматизация бизнес-процессов, архивирование, создание доступных материалов для людей с ограниченными возможностями, а также в мобильных приложениях для перевода текста в реальном времени.

Сравнительный анализ программ для распознавания текста
Рынок программного обеспечения для распознавания текста предлагает разнообразные решения, каждое из которых обладает своими уникальными характеристиками и преимуществами. В 2024 году исследование, проведенное компанией TechInsights, показало, что свыше 75% организаций применяют профессиональные OCR-системы для обработки документов, что подчеркивает важность правильного выбора программного обеспечения. Давайте рассмотрим основные решения, представленные на рынке, начиная с самого популярного – ABBYY FineReader. Эта программа славится своей высокой точностью распознавания, достигающей 99,8%, и способностью одновременно работать с более чем 200 языками. Особенно ценится ее умение сохранять форматирование оригинальных документов, включая таблицы, изображения и сложные макеты.
- Читайте также:
В качестве альтернативы можно рассмотреть Adobe Acrobat Pro DC, который, помимо функций распознавания текста, предлагает обширные возможности для работы с PDF-документами. Интересно, что согласно исследованию Document Solutions Group 2024, около 60% юридических компаний выбирают именно это решение благодаря его надежности и совместимости с различными системами электронного документооборота. Однако стоит отметить, что эта программа менее эффективна при работе с многостраничными документами сложной структуры по сравнению с ABBYY FineReader.
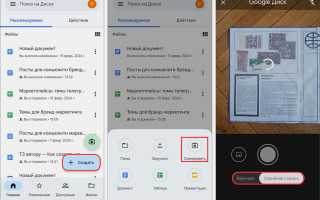
Google Drive представляет собой доступное облачное решение, позволяющее распознавать текст прямо в браузере. Его основным преимуществом является бесплатный базовый функционал и интеграция с другими сервисами Google. Исследование CloudTech Analytics 2024 показало, что около 45% малых предприятий используют эту платформу для выполнения базовых задач распознавания текста. Тем не менее, точность распознавания составляет около 95%, что может быть недостаточно для профессионального использования.
Для мобильных устройств особенно популярны приложения Microsoft Office Lens и Google Keep. Согласно данным Mobile Productivity Report 2024, эти приложения занимают лидирующие позиции по количеству установок среди бизнес-пользователей. Они предлагают удобный интерфейс и возможность быстрого сканирования документов «на ходу», хотя их функционал ограничен по сравнению с десктопными решениями.
| Программа | Точность распознавания | Поддержка языков | Особенности |
|---|---|---|---|
| ABBYY FineReader | 99,8% | 200+ | Сохранение форматирования |
| Adobe Acrobat Pro DC | 98,5% | 50+ | Работа с PDF |
| Google Drive | 95% | 100+ | Облачное хранение |
| Microsoft Office Lens | 93% | 40+ | Мобильная платформа |
Кейсы успешного применения технологий распознавания текста
Рассмотрим реальные примеры, как различные компании внедрили технологии сканирования и распознавания текста для улучшения своих бизнес-процессов. Организация «Логистика-Плюс» столкнулась с задачей обработки значительного объема накладных и транспортных документов — ежедневно необходимо было обрабатывать свыше 500 страниц. После внедрения автоматизированной системы на базе ABBYY FlexiCapture время обработки документов сократилось с 8 часов до 2 часов, а количество ошибок уменьшилось на 90%. Это дало возможность компании оптимизировать работу отдела документооборота и сократить штат сотрудников на 40%.
Другим ярким примером является медицинский центр «Здоровье+», который применил технологии распознавания текста для перевода бумажных медицинских карт пациентов в электронный формат. Благодаря внедрению специализированного решения с поддержкой медицинской терминологии удалось не только оцифровать архив за 3 месяца вместо запланированных 12, но и создать эффективную систему поиска информации в медицинских записях. В результате время, необходимое для поиска нужной информации, сократилось с 30 минут до 2-3 минут.
В образовательной сфере интересным кейсом стало сотрудничество университета имени Ломоносова в проекте оцифровки архивных материалов. Использование комбинированной системы, включающей профессиональные сканеры и программное обеспечение с поддержкой древних шрифтов, позволило не только сохранить исторические документы, но и сделать их доступными для исследователей по всему миру через онлайн-портал. За первый год работы проекта было обработано более 100 000 страниц архивных документов с точностью распознавания 98%.
В банковском секторе стоит отметить опыт Сбербанка, который внедрил систему автоматического распознавания платежных документов. Новая система позволила сократить время обработки платежей с 24 часов до 15 минут, а также минимизировать количество ошибок при вводе данных. По оценкам экспертов, экономический эффект от внедрения составил более 150 миллионов рублей в год только за счет оптимизации трудозатрат и уменьшения количества ошибочных операций.

Распространенные ошибки и способы их предотвращения
При работе с процессами сканирования и распознавания текста многие пользователи сталкиваются с распространенными ошибками, которые могут значительно снизить эффективность работы. Одной из наиболее частых проблем является неверный выбор режима сканирования. Например, применение черно-белого режима для документов, содержащих цветные маркеры или подчеркивания, может привести к утрате важной информации. Артём Викторович Озеров подчеркивает: «Многие пользователи выбирают максимальное разрешение сканирования, считая, что это обеспечит лучшее качество. Однако для большинства офисных документов достаточно 300 dpi, а более высокое разрешение лишь увеличивает размер файла и время обработки».
Еще одной распространенной ошибкой является игнорирование предварительной подготовки документа. Складки, пятна и неравномерное освещение могут значительно ухудшить точность распознавания. Это особенно актуально для документов, отсканированных с помощью мобильных устройств. Евгений Игоревич Жуков отмечает: «При мобильном сканировании крайне важно обеспечить равномерное освещение и стабильное положение устройства. Даже небольшая дрожь камеры может привести к размытию текста и снижению качества распознавания».
 Читайте также:
Читайте также:

Третья распространенная проблема заключается в неправильной настройке зон распознавания. Многие пользователи запускают процесс распознавания всего документа целиком, не выделяя отдельные области с текстом, таблицами или изображениями. Это может привести к тому, что программа будет пытаться распознать графические элементы как текст, что увеличивает количество ошибок и время обработки. Кроме того, часто забывают о важности проверки распознанного текста, особенно при работе с документами, содержащими специализированную терминологию или нестандартные шрифты.
- Неправильный выбор режима сканирования
- Игнорирование подготовки документа
- Ошибки в настройках зон распознавания
- Отсутствие проверки результатов распознавания
- Выбор неподходящего программного обеспечения
Практические рекомендации по оптимизации процесса
Для достижения наилучших результатов в процессе сканирования и распознавания текста следует придерживаться ряда профессиональных советов. В первую очередь, необходимо правильно организовать рабочее пространство, чтобы минимизировать влияние внешних факторов и создать стабильные условия для работы. Подходящее освещение, отсутствие вибраций и правильное размещение оборудования могут значительно улучшить качество получаемых изображений. При обработке больших объемов документов целесообразно разработать четкую систему именования файлов и организовать структурированное хранилище для отсканированных материалов.
Чтобы повысить точность распознавания, стоит применять профили, соответствующие типу обрабатываемых документов. Например, для финансовых бумаг лучше использовать профиль, ориентированный на цифры и таблицы, а для научных статей – профиль, поддерживающий специальные символы и формулы. Регулярное обновление словарей программного обеспечения и обучение системы новым шрифтам и форматам документов, с которыми вы работаете, также играют важную роль.
При работе с конфиденциальными документами необходимо предусмотреть меры по защите информации. Это включает в себя использование защищенных каналов передачи данных, шифрование файлов и регулярное удаление временных файлов после завершения обработки. Рекомендуется также внедрить систему резервного копирования важных данных и разработать четкие инструкции по работе с документами различной степени конфиденциальности.
- Организация структурированного хранилища
- Применение профилей распознавания
- Регулярное обновление словарей
- Внедрение мер по защите информации
- Создание системы резервного копирования
Вопросы и ответы по сканированию и распознаванию текста
-
Как улучшить точность распознавания текста? Для достижения высокой точности распознавания важно использовать качественное оборудование, правильно выбирать режимы сканирования и разрешение. Также необходимо проводить предварительную обработку изображений: корректировать контрастность, устранять шумы и исправлять искажения. При работе с особыми документами полезно обучить систему распознавания конкретным шрифтам и форматам.
-
Что делать, если система не распознает специальные символы? В первую очередь стоит проверить настройки языкового пакета и добавить необходимые наборы символов в словарь программы. Если проблема не решается, можно создать пользовательский шрифт или воспользоваться специализированными модулями распознавания. В некоторых случаях может потребоваться ручная корректировка распознанных символов.
-
Как обрабатывать поврежденные документы? Для работы с поврежденными документами рекомендуется использовать специальные режимы восстановления изображений. Многие современные программы предлагают функции для устранения дефектов, таких как пятна, разрывы и выцветание текста. Также полезно поэкспериментировать с различными настройками контраста и яркости для достижения наилучшего результата.
-
Как организовать массовое сканирование документов? Для массового сканирования лучше всего использовать протяжные сканеры с функцией автоматической подачи документов. Важно заранее подготовить документы, упорядочить их и разработать систему автоматического именования файлов. Также следует настроить пакетную обработку и автоматизировать рутинные операции с помощью макросов или скриптов.
-
Как обеспечить защиту конфиденциальной информации при сканировании? Необходимо использовать защищенные каналы передачи данных, шифровать файлы и ограничивать доступ к оборудованию и программному обеспечению. Важно регулярно очищать временную память устройств и применять специализированное программное обеспечение для защиты информации. Рекомендуется внедрить систему аудита и контроля доступа к документам.
Итоги и рекомендации
Современные технологии сканирования и распознавания текста открывают новые горизонты для цифровизации документооборота. Правильный выбор оборудования и программного обеспечения, соблюдение технологических процессов, а также учет особенностей обрабатываемых документов способствуют высокой эффективности и точности преобразования бумажных материалов в цифровой формат. Необходимо помнить, что успешное внедрение этих технологий зависит не только от технических характеристик используемых решений, но и от грамотной организации всего процесса обработки документов.
Для достижения максимальных результатов рекомендуется:
— Провести анализ текущих процессов документооборота
— Подобрать оборудование и программное обеспечение, соответствующее специфике задач
— Создать четкие инструкции по работе с документами
— Обучить сотрудников правильным методам сканирования и распознавания
— Внедрить систему контроля качества обработки документов
Для получения более подробной консультации по внедрению технологий сканирования и распознавания текста стоит обратиться к профессионалам, которые помогут выбрать оптимальное решение в соответствии с конкретными задачами и требованиями вашей организации.
Будущее технологий распознавания текста
Технологии распознавания текста (OCR — Optical Character Recognition) стремительно развиваются, и их будущее обещает быть еще более захватывающим. С каждым годом мы наблюдаем улучшение точности и скорости распознавания, что открывает новые возможности для различных сфер деятельности.
Одним из ключевых направлений является интеграция искусственного интеллекта и машинного обучения в процессы OCR. Современные алгоритмы способны не только распознавать текст, но и анализировать его контекст, что позволяет значительно повысить качество распознавания, особенно в сложных условиях, таких как нечеткие изображения или нестандартные шрифты.
-
Читайте также:

Кроме того, технологии распознавания текста начинают активно использоваться в мобильных приложениях. С помощью смартфонов пользователи могут быстро сканировать документы, визитки или даже текст на экране, что делает процесс получения информации более удобным и доступным. Это особенно актуально для людей, работающих в сфере бизнеса, образования и здравоохранения, где скорость обработки информации имеет критическое значение.
Важным аспектом будущего технологий OCR является их интеграция с другими системами. Например, распознавание текста может быть связано с системами управления документами, что позволит автоматизировать процессы обработки и хранения информации. Это не только сократит время на выполнение рутинных задач, но и снизит вероятность ошибок, связанных с ручным вводом данных.
Также стоит отметить, что с развитием технологий распознавания текста появляются новые возможности для работы с многоязычными документами. Современные системы способны распознавать и переводить текст на разные языки, что значительно упрощает работу с международными проектами и документами.
Не менее важным является вопрос безопасности и конфиденциальности данных. С увеличением объемов обрабатываемой информации возрастает и необходимость защиты личных данных. Будущее технологий OCR будет связано с разработкой более надежных методов шифрования и защиты информации, что позволит пользователям быть уверенными в безопасности своих данных.
Таким образом, будущее технологий распознавания текста выглядит многообещающе. С каждым годом мы будем наблюдать новые достижения, которые сделают процесс работы с текстовой информацией более эффективным, удобным и безопасным.
Вопрос-ответ
Какие приложения лучше всего подходят для сканирования и распознавания текста?
Существует множество приложений для сканирования и распознавания текста, но наиболее популярные включают Adobe Scan, Microsoft Office Lens и ABBYY FineReader. Эти приложения предлагают высокое качество распознавания, удобный интерфейс и возможность сохранения документов в различных форматах.
Как улучшить качество распознавания текста при сканировании?
Чтобы улучшить качество распознавания текста, убедитесь, что документ хорошо освещен и не имеет теней. Используйте плоскую поверхность для сканирования и избегайте искажений. Также рекомендуется использовать высокое разрешение при сканировании, чтобы текст был четким и разборчивым.
Можно ли распознавать текст на языках, отличных от английского?
Да, многие современные приложения для распознавания текста поддерживают множество языков, включая русский, испанский, французский и другие. Однако качество распознавания может варьироваться в зависимости от языка и шрифта, поэтому стоит протестировать приложение на конкретном языке.
Советы
СОВЕТ №1
Используйте качественное сканирующее устройство. Для достижения наилучших результатов убедитесь, что ваш сканер имеет высокое разрешение (не менее 300 dpi), чтобы текст был четким и легко распознаваемым.
-
Читайте также:

СОВЕТ №2
Проверьте освещение и фон. Если вы используете мобильное приложение для сканирования, убедитесь, что текст хорошо освещен и фон не отвлекает. Это поможет улучшить качество распознавания.
СОВЕТ №3
Выбирайте подходящее программное обеспечение для распознавания текста (OCR). Существует множество приложений и программ, которые предлагают различные функции. Попробуйте несколько, чтобы найти то, которое лучше всего подходит для ваших нужд.
СОВЕТ №4
После распознавания текста обязательно проверьте его на ошибки. Даже лучшие OCR-программы могут допускать ошибки, особенно с нестандартными шрифтами или искаженным текстом. Ручная проверка поможет избежать недоразумений.