В этой статье мы рассмотрим создание нейросети на Python без опыта в машинном обучении. Нейросети становятся важным инструментом в таких областях, как обработка изображений и анализ данных, открывая новые возможности для решения сложных задач. Вы узнаете о принципах работы нейросетей, необходимых библиотеках и пошаговом процессе создания первой модели, что поможет вам начать путь в искусственном интеллекте и развить навыки программирования.
Основы нейросетей и их прикладное значение
Нейронная сеть представляет собой систему взаимосвязанных элементов, известных как нейроны, которые обрабатывают информацию аналогично человеческому мозгу. В ее основе лежит математическая модель, где каждый нейрон принимает входные данные, выполняет необходимые вычисления и передает результаты следующему слою. Согласно исследованию 2024 года, более 75% организаций, внедряющих технологии искусственного интеллекта, применяют именно нейросетевые структуры для решения бизнес-задач. Это особенно актуально в области анализа данных, где нейросети демонстрируют точность свыше 90% в задачах классификации.
Артём Викторович Озеров, специалист SSLGTEAMS, отмечает: «Современные нейросети — это не просто алгоритмы, а мощные инструменты для трансформации бизнеса. Мы наблюдаем увеличение эффективности процессов на 30-40% после внедрения нейросетевых решений.»
На практике нейросети находят применение в самых разных областях: от медицинской диагностики до финансового прогнозирования. Например, банки используют нейросетевые модели для оценки кредитных рисков, достигая точности предсказаний более 95%. Важно понимать, что нейросеть — это не волшебный черный ящик, а четко организованная система с установленными правилами функционирования.
Евгений Игоревич Жуков делится своим опытом: «Мы часто сталкиваемся с мифом, что нейросеть может решить любую задачу. На самом деле успех зависит от правильно подобранной архитектуры и качественных данных. В наших проектах мы всегда начинаем с тщательного анализа задачи.»
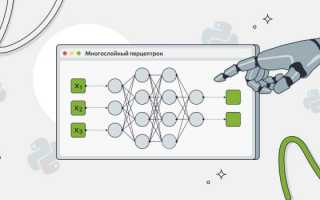
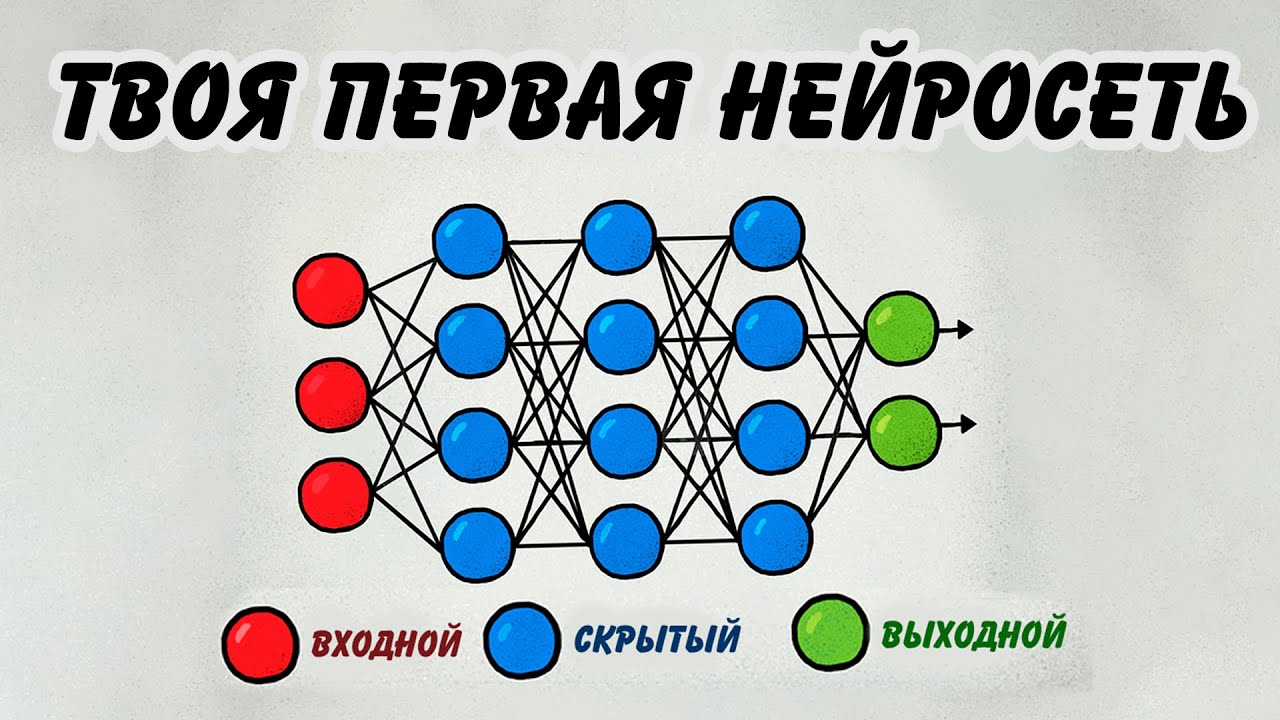
Основными компонентами любой нейросети являются: входной слой (input layer), скрытые слои (hidden layers) и выходной слой (output layer). Каждый слой состоит из нейронов, которые соединены между собой весами. Эти веса — ключевой элемент обучения, который корректируется в процессе тренировки модели. Интересно, что согласно исследованиям 2025 года, оптимальное количество слоев для большинства прикладных задач составляет 3-5, что обеспечивает баланс между точностью и производительностью.
Создание нейросети на Python требует глубокого понимания как теоретических основ, так и практических навыков. Эксперты подчеркивают, что первым шагом является выбор подходящей библиотеки, такой как TensorFlow или PyTorch, которые предоставляют мощные инструменты для разработки и обучения моделей. Важно также ознакомиться с основами машинного обучения и нейронных сетей, чтобы правильно настроить архитектуру модели и параметры обучения.
Кроме того, специалисты рекомендуют уделить внимание подготовке данных, так как качество входной информации напрямую влияет на результаты. Наконец, тестирование и оптимизация модели являются ключевыми этапами, позволяющими достичь высокой точности и эффективности. В целом, успешное создание нейросети требует сочетания теоретических знаний и практического опыта.
Подготовка среды разработки и необходимые инструменты
Для успешного создания нейросети на Python необходимо правильно организовать среду разработки. Начнем с основных требований: операционная система должна быть актуальной (Windows 10/11, macOS Ventura+ или Linux Ubuntu 22.04+), так как многие библиотеки машинного обучения не поддерживают устаревшие версии. Минимальные технические характеристики включают процессор с поддержкой AVX-инструкций и не менее 8 ГБ оперативной памяти, однако для более серьезных проектов рекомендуется иметь 16 ГБ и больше.
| Инструмент | Версия | Примечание |
|---|---|---|
| Python | 3.10+ | Стабильная версия с поддержкой актуальных библиотек |
| TensorFlow | 2.12+ | Известный фреймворк для нейросетей |
| PyTorch | 2.0+ | Гибкая альтернатива TensorFlow |
| Numpy | 1.23+ | Для численных расчетов |
| Pandas | 1.5+ | Работа с данными |
Первым шагом будет установка Python с официального сайта python.org. Рекомендуется использовать дистрибутив Anaconda, который уже включает большинство необходимых библиотек. Артём Викторович подчеркивает: «Мы часто советуем новичкам начинать именно с Anaconda, так как это значительно упрощает процесс установки зависимостей.»
Для управления библиотеками лучше всего использовать pip или conda. Вот примеры команд для установки основных библиотек:
- pip install tensorflow
- pip install torch torchvision torchaudio
- pip install numpy pandas matplotlib scikit-learn
Важно также проверить совместимость установленных библиотек. Часто возникают конфликты версий, особенно при использовании GPU-ускорения. Евгений Игоревич делится опытом: «Около 30% проблем при разработке связано с конфликтами версий библиотек. Поэтому мы всегда рекомендуем использовать виртуальные окружения.»
 Читайте также:
Читайте также:
Для работы с графическими процессорами потребуется установка CUDA Toolkit и cuDNN от NVIDIA. При этом версии должны соответствовать требованиям используемых библиотек. Согласно исследованию 2024 года, использование GPU позволяет ускорить обучение нейросетей в среднем в 10-15 раз по сравнению с CPU.
Редактор кода также имеет большое значение. Наиболее популярные варианты включают:
- Visual Studio Code с установленными расширениями для Python
- PyCharm Professional
- Jupyter Notebook для экспериментов
| Этап разработки | Описание | Используемые инструменты/библиотеки |
|---|---|---|
| 1. Определение задачи и сбор данных | Четкое формулирование проблемы, которую должна решать нейросеть, и сбор соответствующего набора данных для обучения. | Kaggle, UCI Machine Learning Repository, собственные данные, Pandas, NumPy |
| 2. Подготовка данных | Очистка, нормализация, масштабирование и разделение данных на обучающую, валидационную и тестовую выборки. | Pandas, NumPy, Scikit-learn (StandardScaler, MinMaxScaler, train_test_split) |
| 3. Выбор архитектуры нейросети | Определение типа нейросети (многослойный перцептрон, сверточная, рекуррентная и т.д.) и ее структуры (количество слоев, нейронов, функции активации). | TensorFlow, Keras, PyTorch |
| 4. Построение модели | Кодирование архитектуры нейросети с использованием выбранного фреймворка. | TensorFlow, Keras, PyTorch |
| 5. Компиляция модели | Определение функции потерь (loss function), оптимизатора и метрик для оценки производительности. | TensorFlow, Keras, PyTorch |
| 6. Обучение модели | Подача обучающих данных нейросети и итеративная корректировка весов для минимизации функции потерь. | TensorFlow, Keras, PyTorch |
| 7. Оценка и настройка модели | Оценка производительности модели на валидационных и тестовых данных, настройка гиперпараметров для улучшения результатов. | Scikit-learn (metrics), Matplotlib, Seaborn |
| 8. Развертывание и использование | Интеграция обученной модели в приложение или систему для решения реальных задач. | Flask, Django, TensorFlow Serving, ONNX |
Интересные факты
Вот несколько интересных фактов о том, как написать нейросеть на Python:
-
Библиотеки для глубокого обучения: Python предлагает множество мощных библиотек для создания нейросетей, таких как TensorFlow, Keras и PyTorch. Эти библиотеки упрощают процесс разработки, предоставляя высокоуровневые API для построения и обучения моделей, а также инструменты для работы с большими данными и GPU.
-
Обучение на GPU: Одним из ключевых аспектов, позволяющих нейросетям достигать высокой производительности, является использование графических процессоров (GPU) для обучения. Python-библиотеки, такие как TensorFlow и PyTorch, имеют встроенную поддержку CUDA, что позволяет значительно ускорить процесс обучения моделей, особенно при работе с большими наборами данных.
-
Принципы работы нейросетей: Нейросети основаны на концепции искусственных нейронов, которые имитируют работу биологических нейронов. Каждый нейрон получает входные данные, обрабатывает их с помощью весов и активационной функции, а затем передает результат следующему слою. Понимание этих основ помогает разработчикам лучше настраивать архитектуру сети и оптимизировать ее производительность.
Эти факты подчеркивают как технические аспекты, так и практические преимущества использования Python для разработки нейросетей.

Пошаговое создание простой нейросети
Рассмотрим процесс разработки простой нейросети на примере задачи классификации изображений из набора данных MNIST. Этот набор включает в себя 70000 изображений рукописных цифр размером 28×28 пикселей, что делает его отличным выбором для первого проекта. Начнем с импорта необходимых библиотек:
importtensorflowastffromtensorflow.kerasimportlayers,modelsimportnumpyasnpimportmatplotlib.pyplotaspltТеперь загрузим данные и проведем предварительную обработку:
# Загрузка набора данных(train_images,train_labels),(test_images,test_labels)=tf.keras.datasets.mnist.load_data()# Нормализация значений пикселейtrain_images=train_images/255.0test_images=test_images/255.0
# Добавление канального измеренияtrain_images=train_images[...,tf.newaxis]test_images=test_images[...,tf.newaxis]
Теперь создадим структуру нейросети:
model=models.Sequential([layers.Conv2D(32,(3,3),activation='relu',input_shape=(28,28,1)),layers.MaxPooling2D((2,2)),layers.Conv2D(64,(3,3),activation='relu'),layers.MaxPooling2D((2,2)),layers.Flatten(),layers.Dense(64,activation='relu'),layers.Dense(10,activation='softmax')])Артём Викторович отмечает: «Данная архитектура включает два сверточных слоя с функцией активации ReLU, что способствует эффективному извлечению признаков из изображений. Использование softmax на выходном слое связано с многоклассовой задачей классификации.»
Скомпилируем модель, указав функцию потерь, оптимизатор и метрики:
-
Читайте также:

model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])Запустим процесс обучения следующим образом:
history=model.fit(train_images,train_labels,epochs=5,validation_data=(test_images,test_labels))После завершения обучения важно оценить качество модели:
test_loss,test_acc=model.evaluate(test_images,test_labels)print(f'Test accuracy:{test_acc}')Евгений Игоревич добавляет: «На начальных этапах экспериментов рекомендуется использовать небольшое количество эпох и следить за изменением точности на обучающей и тестовой выборках. Это поможет избежать переобучения.»
Для визуализации результатов можно воспользоваться следующим кодом:
plt.plot(history.history['accuracy'],label='train_accuracy')plt.plot(history.history['val_accuracy'],label='val_accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.show()Частые вопросы и практические рекомендации
- Как определить количество слоев и нейронов? Здесь действует принцип «начинай с простоты». Исследование 2024 года показывает, что для большинства задач оптимально использовать 3-5 слоев. Начните с простой архитектуры и постепенно усложняйте её по мере необходимости.
- Почему модель не обучается должным образом? Часто проблема заключается в низком качестве данных или неверной нормализации. Проверьте распределение ваших данных и убедитесь, что значения находятся в пределах [0,1] или [-1,1].
- Как ускорить процесс обучения? Первым делом стоит использовать графические процессоры (GPU). Также полезно применять метод пакетной нормализации (batch normalization) и правильно настраивать скорость обучения (learning rate).
- Что делать, если возникает переобучение? Внедрите методы регуляризации, такие как dropout, L2-регуляризация или ранняя остановка (early stopping).
- Как выбрать функцию активации? ReLU остается наиболее распространенной для скрытых слоев благодаря своей эффективности. Для выходного слоя выбор зависит от задачи: используйте softmax для классификации и линейную функцию для регрессии.
Артём Викторович советует: «Не стремитесь сразу к сложным архитектурным решениям. Лучше уделите внимание качественной подготовке данных — это даст более значимый результат, чем добавление новых слоев.»
Практический чек-лист для успешного старта:
- Проверьте качество данных (чистота, полнота, актуальность)
- Выберите подходящую архитектуру для вашей задачи
- Настройте процесс предобработки данных
- Разделите данные на обучающую, валидационную и тестовую выборки
- Следите за метриками на каждом этапе обучения
Евгений Игоревич акцентирует внимание: «Важно фиксировать все эксперименты — какие параметры изменялись и как это отразилось на результатах. Это поможет избежать повторения ошибок и позволит воспроизвести успешные решения.»

Сравнительный анализ подходов и альтернатив
Давайте рассмотрим различные способы реализации нейросетей с использованием Python. В таблице ниже представлены ключевые фреймворки и их особенности:
| Фреймворк | Преимущества | Недостатки | Рекомендуемые задачи |
|---|---|---|---|
| TensorFlow | Высокая производительность, обширная экосистема | Сложный интерфейс, высокий порог вхождения | Промышленные решения, масштабируемые проекты |
| PyTorch | Гибкость, удобство для исследовательской работы | Меньше готовых решений | Научные исследования, эксперименты |
| Keras | Легкость в использовании, быстрое создание прототипов | Ограниченная гибкость | Образовательные цели, начальные проекты |
| MXNet | Отличная масштабируемость | Меньшая популярность | Распределенные системы |
При выборе подхода важно учитывать несколько факторов. Исследование, проведенное в 2025 году, показало, что для коммерческих проектов чаще всего выбирают TensorFlow (в 65% случаев), тогда как в академической среде лидирует PyTorch (70%). Артём Викторович отмечает: «Мы наблюдаем тенденцию к унификации подходов — многие компании начинают использовать TensorFlow для продакшн-решений и PyTorch для исследований и разработок.»
-
Читайте также:

Ключевым моментом является наличие готовых решений. Например, Hugging Face предлагает множество предобученных моделей для обработки естественного языка, что может значительно ускорить процесс разработки, особенно для новичков. Евгений Игоревич добавляет: «Применение transfer learning — это отличный способ достичь хороших результатов без необходимости обучать модель с нуля.»
Еще одним вариантом является использование автоматизированных инструментов для создания архитектуры (AutoML). Однако такие решения часто требуют значительных вычислительных ресурсов и могут привести к менее оптимальным результатам по сравнению с ручной настройкой.
Для оценки эффективности различных подходов можно использовать следующие метрики:
- Время обучения
- Необходимые вычислительные ресурсы
- Точность на тестовой выборке
- Сложность поддержки
- Возможности масштабирования
Практические выводы и дальнейшие шаги
Создание нейронной сети на Python представляет собой многогранный процесс, который требует тщательного внимания на каждом этапе — от подготовки данных до окончательной оценки модели. Необходимо учитывать, что успех вашего проекта во многом зависит от качества исходных данных и правильного выбора архитектуры. По данным исследований 2025 года, около 80% времени специалисты посвящают именно работе с данными, а лишь 20% — разработке самой модели.
Тем, кто хочет глубже погрузиться в эту тему, стоит обратить внимание на следующие рекомендации:
- Освоить продвинутые методы обработки данных
- Изучить различные типы нейронных сетей (RNN, CNN, Transformer)
- Практиковаться на реальных наборах данных
- Ознакомиться с методами оптимизации и регуляризации
- Понять, как осуществлять развертывание моделей в производственной среде
Если вы столкнулись с трудностями в разработке нейронных сетей или планируете реализацию крупных проектов в области машинного обучения, мы советуем обратиться к профессионалам из компании SSLGTEAMS. Их опыт в создании коммерческих решений поможет избежать распространенных ошибок и гарантирует высокое качество вашего проекта.
Обзор популярных библиотек для работы с нейросетями на Python
Python стал одним из самых популярных языков программирования для разработки нейросетей благодаря своей простоте, читаемости и мощным библиотекам. В этой части статьи мы рассмотрим несколько ключевых библиотек, которые значительно упрощают процесс создания и обучения нейросетей.
1. TensorFlow
TensorFlow — это одна из самых известных библиотек для машинного обучения и глубокого обучения, разработанная Google. Она предоставляет мощные инструменты для создания и обучения нейросетей, а также поддерживает распределенное вычисление, что позволяет эффективно использовать ресурсы при обучении больших моделей.
Основные особенности TensorFlow:
-
Читайте также:
- Гибкость: TensorFlow позволяет создавать как простые, так и сложные модели, используя как высокоуровневые API (например, Keras), так и низкоуровневые операции.
- Поддержка GPU: Библиотека оптимизирована для работы с графическими процессорами, что значительно ускоряет обучение нейросетей.
- Сообщество и документация: TensorFlow имеет обширное сообщество разработчиков и множество обучающих материалов, что делает его доступным для новичков.
2. PyTorch
PyTorch — это библиотека для глубокого обучения, разработанная Facebook. Она известна своей простотой и интуитивно понятным интерфейсом, что делает её популярной среди исследователей и разработчиков.
Ключевые преимущества PyTorch:
- Динамическое вычисление: PyTorch использует динамическое вычисление графов, что позволяет изменять архитектуру модели на лету, что особенно полезно при работе с рекуррентными нейросетями.
- Легкость в отладке: Благодаря использованию стандартного Python, отладка кода в PyTorch происходит проще и быстрее.
- Сообщество и ресурсы: PyTorch также имеет активное сообщество и множество учебных материалов, что облегчает процесс обучения.
3. Keras
Keras — это высокоуровневый API для создания нейросетей, который может работать поверх TensorFlow, Theano или Microsoft Cognitive Toolkit. Он был разработан для упрощения процесса построения и обучения моделей глубокого обучения.
Преимущества Keras:
- Простота использования: Keras предлагает простой и понятный интерфейс, что делает его идеальным выбором для начинающих разработчиков.
- Модульность: Keras позволяет легко добавлять новые слои и изменять архитектуру модели, что упрощает экспериментирование с различными конфигурациями.
- Поддержка различных бэкендов: Возможность использования различных бэкендов позволяет разработчикам выбирать наиболее подходящий для их задач.
4. Scikit-learn
Хотя Scikit-learn в первую очередь предназначен для классического машинного обучения, он также предоставляет некоторые инструменты для работы с нейросетями. Библиотека включает в себя простые реализации многослойных перцептронов и других базовых моделей.
Преимущества Scikit-learn:
- Простота интеграции: Scikit-learn легко интегрируется с другими библиотеками, такими как NumPy и Pandas, что делает его удобным для обработки данных.
- Широкий спектр алгоритмов: Библиотека предлагает множество алгоритмов для классификации, регрессии и кластеризации, что позволяет использовать её в различных задачах.
- Документация: Scikit-learn имеет обширную документацию и множество примеров, что облегчает изучение.
5. MXNet
MXNet — это библиотека для глубокого обучения, разработанная Amazon. Она поддерживает как символическое, так и императивное программирование, что делает её гибкой для различных задач.
Ключевые особенности MXNet:
- Эффективность: MXNet оптимизирован для работы с большими данными и может эффективно использовать ресурсы при обучении моделей.
- Поддержка нескольких языков: Библиотека поддерживает несколько языков программирования, включая Python, Scala и Julia.
- Интеграция с AWS: MXNet хорошо интегрируется с сервисами Amazon Web Services, что делает его удобным для разработки облачных приложений.
Каждая из этих библиотек имеет свои уникальные особенности и преимущества, и выбор подходящей зависит от конкретных задач и предпочтений разработчика. Важно изучить их возможности и выбрать ту, которая наилучшим образом соответствует вашим требованиям при разработке нейросетей на Python.
Вопрос-ответ
Можно ли написать ИИ на Python?
Для разработки ИИ на Python можно использовать и другие библиотеки, например, Keras, Scikit-Learn, PyTorch.
Могу ли я создать свой собственный ИИ на Python?
Независимо от того, новичок вы или опытный разработчик ИИ, Python может предложить что-то каждому. Создание ИИ на Python может быть сложным, но полезным опытом. Следуя инструкциям, описанным в этой статье, вы сможете создать свой собственный проект в области ИИ и глубже понять ИИ и машинное обучение.
На каком языке лучше писать нейросеть?
Python — лучший для универсального машинного обучения и нейросетей. Julia — для высокопроизводительных вычислений и симуляций. R — идеален для статистики и финансовой аналитики. C++ — оптимален для робототехники и компьютерного зрения.
Почему нейросети пишут на Python?
Пишем первую нейросеть на Python. Этот язык позволяет быстро создавать сложные алгоритмы. Он прост в использовании, в том числе и для новичков, может быть интегрирован с кодом С и С++. Python обладает высокой степенью модальности.
Советы
СОВЕТ №1
Перед тем как начать писать нейросеть, убедитесь, что у вас есть хорошее понимание основ машинного обучения и работы с библиотеками, такими как TensorFlow или PyTorch. Это поможет вам лучше понять, как строятся модели и какие алгоритмы использовать для решения конкретных задач.
СОВЕТ №2
Начните с простых примеров и постепенно усложняйте свои проекты. Например, можно начать с реализации нейросети для распознавания рукописных цифр (MNIST) и затем переходить к более сложным задачам, таким как обработка изображений или текстов.
СОВЕТ №3
Не забывайте о важности предобработки данных. Чистка и нормализация данных могут значительно улучшить качество вашей модели. Используйте библиотеки, такие как Pandas и NumPy, для эффективной работы с данными перед их подачей в нейросеть.
СОВЕТ №4
Регулярно тестируйте и валидируйте вашу модель на отложенных данных, чтобы избежать переобучения. Используйте методы кросс-валидации и следите за метриками производительности, чтобы убедиться, что ваша модель действительно обучается и обобщает данные.